By: Kevin Miudo
Geovis Project Assignment @RyersonGeo, SA8905, Fall 2018
https://www.youtube.com/watch?v=Il6nINBqNYw&feature=youtu.be
Introduction
In this online development blog for my created map animation, I intend to discuss the steps involved in producing my final geovisualization product, which can be viewed above in the embedded youtube link. It is my hope that you, the reader, learn something new about GIS technologies and can apply any of the knowledge contained within this blog towards your own projects. Prior to discussing the technical aspects of the map animations development, I would like to provide some context behind the creation of my map animation.
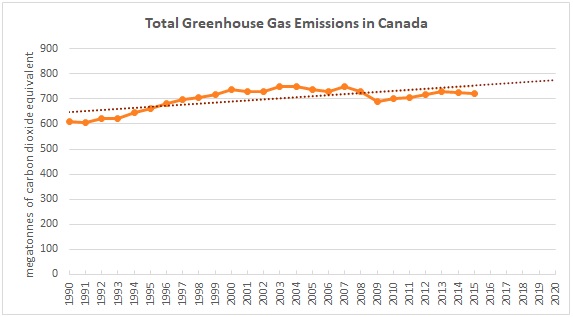
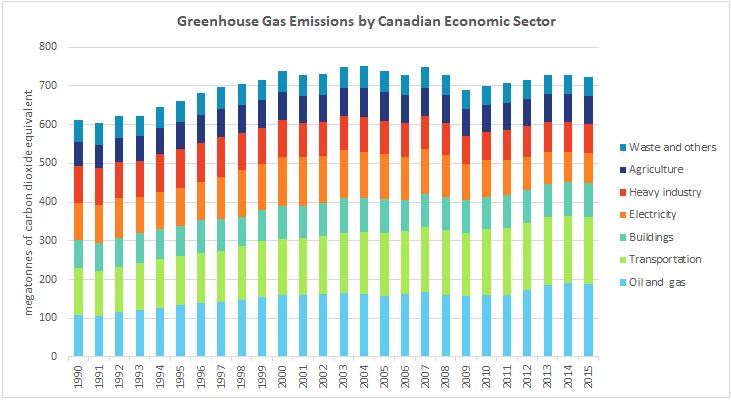
Cities within developing nations are experiencing urban growth at a rapid rate. Both population and sprawl are increasing at unpredictable rates, with consequences for environmental health and sustainability. In order to explore this topic, I have chosen to create a time series map animation visualizing the growth of urban land use in a developing city within the Global South. The City which I have chosen is Sào Paulo, Brazil. Sào Paulo has been undergoing rapid urban growth over the last 20 years. This increase in population and urban sprawl has significant consequences to climate change, and such it is important to understand the spatial trend of growth in developing cities that do not yet have the same level of control and policies in regards to environmental sustainability and urban planning. A map animation visualizing not only the extent of urban growth, but when and where sprawl occurs, can help the general public get an idea of how developing cities grow.
Data Collection
In-depth searches of online open data catalogues for vector based land use data cultivated little results. In the absence of detailed, well collected and precise land use data for Sào Paulo, I chose to analyze urban growth through the use of remote sensing. Imagery from Landsat satellites were collected, and further processed in PCI Geomatica and ArcGIS Pro for land use classification.
Data collection involved the use of open data repositories. In particular, free remotely sensed imagery from Landsat 4, 5, 7 and 8 can be publicly accessed through the United States Geological Survey Earth Explorer web page. This open data portal allows the public to collect imagery from a variety of satellite platforms, at varying data levels. As this project aims to view land use change over time, imagery was selected at data type level-1 for Landsat 4-5 Thematic Mapper and Landsat 8 OLI/TIRS. Imagery selected had to have at least less than 10% cloud cover, and had to be images taken during the daytime so that spectral values would remain consistent across each unsupervised image classification.

Landsat 4-5 imagery at 30m spectral resolution was used for the years between 2004 and 2010. Landsat-7 Imagery at 15m panchromatic resolution was excluded from search criteria, as in 2003 the scan-line corrector of Landsat-7 failed, making many of its images obsolete for precise land use analysis. Landsat 8 imagery was collected for the year 2014 and 2017. All images downloaded were done so at the Level-1 GeoTIFF Data Product level. In total, six images were collected for years 2004, 2006, 2007, 2008, 2010, 2014, 2017.
Data Processing
Imagery at the Level-1 GeoTIFF Data Product Level contains a .tif file for each image band produced by Landsat 4-5 and Landsat-8. In order to analyze land use, the image data must be processed as a single .tiff. PCI Geomatica remote sensing software was employed for this process. By using the File->Utility->Translate command within the software, the user can create a new image based on one of the image bands from the Landsat imagery.

For this project, I selected the first spectral band from Landsat 4-5 Thematic Mapper images, and then sequentially added bands 2,3,4,5, and band 7 to complete the final .tiff image for that year. Band 6 is skipped as it is the thermal band at 120m spatial resolution, and is not necessary for land use classification. This process was repeated for each landsat4-5 image.Similarly for the 2014 and 2017 Landsat-8 images, bands 2-7 were included in the same manner, and a combined image was produced for years 2014 and 2017.

Each combined raster image contained a lot of data, more than required to analyze the urban extent of Sào Paulo and as a result the full extent of each image was clipped. When doing your own map animation project, you may also wish to clip data to your study area as it is very common for raw imagery to contain sections of no data or clouds that you do not wish to analyze. Using the clipping/subsetting option found under tools in the main panel of PCI Geomatica Focus, you can clip any image to a subset of your choosing. For this project, I selected the coordinate type ‘lat/long’ extents and input data for my selected 3000×3000 pixel subset. The input coordinates for my project were: Upper left: 46d59’38.30″ W, Upper right: 23d02’44.98″ S, Lower right: 46d07’21.44″ W, Lower Left: 23d52’02.18″ S.

Land Use Classification
The 7 processed images were then imported into a new project in ArcPro. During importation, raster pyramids were created for each image in order to increase processing speeds. Within ArcPro, the Spatial Analyst extension was activated. The spatial analyst extension allows the user to perform analytical techniques such as unsupervised land use classification using iso-clusters. The unsupervised iso-clusters tool was used on each image layer as a raster input.

The tool generates a new raster that assigns all pixels with the same or similar spectral reluctance value a class. The number of classes is selected by the user. 20 classes were selected as the unsupervised output classes for each raster. It is important to note that the more classes selected, the more precise your classification results will be. After this output was generated for each image, the 20 spectral classes were narrowed down further into three simple land use classes. These classes were: vegetated land, urban land cover, and water. As the project primarily seeks to visualize urban growth, and not all types of varying land use, only three classes were necessary. Furthermore, it is often difficult to discern between agricultural land use and regular vegetated land cover, or industrial land use from residential land use, and so forth. Such precision is out of scope for this exercise.
The 20 classes were manually assigned, using the true colour .tiff image created from the image processing step as a reference. In cases where the spectral resolution was too low to precisely determine what land use class a spectral class belong to, google maps was earth imagery referenced. This process was repeated for each of the 7 images.
After the 20 classes were assigned, the reclassify tool under raster processing in ArcPro was used to aggregate all of the similar classes together. This outputs a final, reclassified raster with a gridcode attribute that assigns respective pixel values to a land use class. This step was repeated for each of the 7 images. With the reclassify tool, you can assign each of the output spectral classes to new classes that you define. For this project, the three classes were urban land use, vegetated land, and water.

Cartographic Element Choices:
It was at this point within ArcPro that I had decided to implement my cartographic design choices prior to creating my final map animation.
For each layer, urban land use given a different shade of red. The later the year, the darker and more opaque the colour of red. Saturation and light used in this manner helps assist the viewer to indicate where urban growth is occurring. The darker the shade of red, the more recent the growth of urban land use in the greater Sào Paulo region. In the final map animation, this will be visualized through the progression of colour as time moves on in the video.
ArcPro Map Animation:
Creating an animation in ArcPro is very simple. First, locate the animation tab through the ‘View’ panel in ArcPro, then select ‘Add animation’. Doing so will open a new window below your work space that will allow the user to insert keyframes. The animation tab contains plenty of options for creating your animation, such as the time frame between key frames, and effects such as transitions, text, and image overlays.

For the creation of my map animation, I started with zoomed-out view of South America in order to provide the viewer with some context for the study area, as the audience may not be very familiar with the geography of Sào Paulo. Then, using the pan tool, I zoomed into select areas of choice within my study area, ensuring to create new keyframes every so often such that the animation tool creates a fly-by effect. The end result explores the very same mapping extents as I viewed while navigating through my data.

While making your own map animation, ensure to play through your animation frequently in order to determine that the fly-by camera is navigating in the direction you want it to. The time between each keyframe can be adjusted in the animation panel, and effects such as text overlays can be added. Each time I activated another layer for display to show the growth of urban land use from year to year, I created a new keyframe and added a text overlay indicating to the user the date of the processed image.
Once you are satisfied with your results, you can export your final animation in a variety of formats, such as .avi, .mov, .gif and more. You can even select the type of resolution, or use a preset that automatically configures your video format for particular purposes. I chose the youtube export format for a final .mpeg4 file at 720p resolution.
I hope this blog was useful in creating your very own map animation on remotely sensed and classified raster data. Good luck!












































 the layers I just created in a 3D environment. From the “Create Tab”, I selected “Create Scene”. A scene viewer page opened and the virtual 3D globe which I used to display my layers was generated. Using the “Modify Scene” tab, I added my six layers that I formatted in the map view from my content. As this scene will become the base of the mapping application, it is important that I configured all the desired setting in the scene view, as these settings will not be able to be changed in the application itself. For example, I altered the order of the layers in my legend, chose a basemap, specified the suns position in the sky, and optimized the performance of the scene in scene settings by ensuring the 3D graphics slide bar was set to Performance rather than quality. I then saved the scene and navigated back to “My Content”.
the layers I just created in a 3D environment. From the “Create Tab”, I selected “Create Scene”. A scene viewer page opened and the virtual 3D globe which I used to display my layers was generated. Using the “Modify Scene” tab, I added my six layers that I formatted in the map view from my content. As this scene will become the base of the mapping application, it is important that I configured all the desired setting in the scene view, as these settings will not be able to be changed in the application itself. For example, I altered the order of the layers in my legend, chose a basemap, specified the suns position in the sky, and optimized the performance of the scene in scene settings by ensuring the 3D graphics slide bar was set to Performance rather than quality. I then saved the scene and navigated back to “My Content”.

{kind=link}
{kind=link}
{kind=link}
.gif){kind=link}